
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 자료구조와함께배우는알고리즘입문
- 처음 만나는 AI수학 with Python
- network configuration
- 알파회계
- d
- 스프링부트핵심가이드
- Kernighan의 C언어 프로그래밍
- 코드로배우는스프링웹프로젝트
- 코드로배우는스프링부트웹프로젝트
- 서버설정
- 페이징
- 자료구조와 함께 배우는 알고리즘 입문
- 리눅스
- /etc/network/interfaces
- 구멍가게코딩단
- 이터레이터
- 목록처리
- 자바편
- 처음 만나는 AI 수학 with Python
- 데비안
- resttemplate
- GIT
- 네트워크 설정
- baeldung
- 선형대수
- ㅒ
- 스프링 시큐리티
- 티스토리 쿠키 삭제
- iterator
- 친절한SQL튜닝
- Today
- Total
bright jazz music
퀵 정렬(Quick Sort) 일반형 본문
퀵 정렬은 비교 정렬에 속한다. 비교 정렬이란 버블 정렬과 같은 분류인데, 버블정렬이 자신의 다음 인덱스의 원소와 비교해 정렬해 나가는 것처럼 퀵 정렬은 피벗(pivot)을 선택하여 비교 기준점을 만들고 비교하며 정렬을 진행한다.
퀵 정렬은 3단계로 진행된다.
- 1단계: 배열 중 원소 하나를 선택한다. 이 원소를 피벗이라고 한다.
- 2단계: 피벗 앞에는 피벗보다 작은 값의 원소를 두고, 피벗 뒤에는 값이 큰 원소들이 오도록 배열을 '분할'한다. 분할 후 피벗의 위치는 변경되지 않는다.
- 분할된 2개의 작은 배열에 대해 앞의 과정을 반복한다. 배열의 크기가 0 또는 1이 될 때까지 반복한다.
퀵 정렬과 합병정렬은 유사해 보이지만 차이가 있다. 합병정렬은 언제나 배열을 균등하게 절반으로 나누어 비교하지만, 퀵 정렬은 임시 원소를 기준으로 비균등하게 나누어 비교한다.
function quickSort(arr) {
if(arr.length <= 1) {
return arr;
}
// 임의로 피벗을 배열의 0으로 지정. 배열 내의 랜덤 값을 선택해도 됨.
//const pivot = arr[0]
//임의의 값 지정
const pivot = arr[Math.floor(arr.length / 2)]
let left = []
let right = []
for(let i=0; i < arr.length; i++) {
if(arr[i] < pivot) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
return [...quickSort(left), pivot, ...quickSort(right)]
}
퀵 정렬은 최선과 평균의 경우 O(n log n)이지만 최악에서는 O(n**2)을 보인다.
퀵 정렬이 최악인 상황은 이미 배열이 정렬되었거나 거의 정렬된 배열이다. 퀵 정렬이 최악의 복잡도를 보이는 경우에는 피벗이 항상 최솟값이나 최댓값으로 선택되어 분할이 불균등하게 이루어지고 재귀적인 호출에 의해 정렬 속도가 느려지는 현상이 발생할 수 있다. 최악의 경우를 피하고자 피벗을 선택하는 방법을 최적화 하는 방법들이 있다. e.g. median of medians
그러한 면에서 거의 정렬된 배열에서 앞쪽 인덱스를 피봇하여 퀵정렬을 하게 되면 성능이 좋지 않다. 위의 코드의 경우 0번 인덱스를 사용하는 경우가 그렇다.
퀵 정렬의 공간 복잡도는 재귀적 요청을 발생시키므로 n에 비례해 증가하는 값이다. 그러나 연산이 반복될수록 반환되는 좌우 배열의 사이즈가 줄어들어 0 또는 1로 수렴하고, 해당 배열은 더 이상의 연산이 필요하지 않게 된다. 이러한 경우 퀵 정렬의 공간 복잡도는 O(log n)이 되는 데, 최악의 경우라면 O(n)이 된다.
일반형은 위와 같지만 아래와 같이 하면 조금 더 개선할 수 있다.
function quickSort(arr) {
if (arr.length <= 1) {
return arr;
}
// 피벗을 랜덤하게 선택하면 더 효율적. 최악의 경우를 면할 확률 높아짐.
const pivot = arr[Math.floor(arr.length / 2)];
const left = [];
const right = [];
const equal = []; // 피벗과 같은 값을 저장
// 피벗을 제외한 나머지 원소들을 분류
for (let i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else if (arr[i] > pivot) {
right.push(arr[i]);
} else {
equal.push(arr[i]);
}
}
// 일반형에서 원소가 피벗값보다 큰 경우 오른쪽 배열에 담기게 되는데,
// 이 경우에는 따로 분리함으로써 오른쪽 배열의 재귀 호출 횟수를 줄인다.
return [...quickSort(left), ...equal, ...quickSort(right)];
}
예제1)
/*
가난한 헬스 매니아의 단백질 찾기
가진 돈을 최대한 활용해 가장 많은 단백질을 확보하는 코드 작성
*/
const MAX_FOOD_COUNT = 4; //최대 섭취 가능 음식의 수
const PROTEIN_LIST = [5, 15, 22, 36, 46, 48];
const PRICE_LIST = [3000, 4100, 4500, 5000, 5600, 5900] // 음식의 가격
let budget = 15000; // 가진 돈
// 함량율 리스트
const ratioList = PROTEIN_LIST.map((protein, index) => {
return {
index: index,
ratio: protein / PRICE_LIST[index]
}
}
)
function quickSort(array, left = 0, right = array.length - 1) {
if(left < right) {
let pivot = partition(array, left, right);
// 피벗값
quickSort(array, left, pivot - 1);
quickSort(array, pivot + 1, right);
}
return array;
}
// 분할 함수
function partition(array, left, right) {
// 오른쪽 값을 인덱스로 하여 함량을 피벗값으로 설정
let pivot = array[right].ratio;
//왼쪽값은 i에 할당
let i = left;
// 왼쪽값을 j에도 할당하고 그 값이 오른쪽값보다 작은 경우 반복
for(let j = left; j < right; j++) {
//만약 배열의 j번째 값이 피벗값보다 크다면
if(array[j].ratio > pivot) {
// 배열의 i번째 값과 j번째 값을 교환하고 i값을 1증가
[array[i], array[j]] = [array[j], array[i]];
i++;
}
}
// i번째 값과 오른쪽값을 교환
[array[i], array[right]] = [array[right], array[i]];
// i값을 반환
return i;
}
// 가격 대비 함량이 높은 음식부터 퀵정렬
quickSort(ratioList);
let totalProtein = 0;
let foodCount = 0;
// 예산 내에서 가장 단백질 함량이 높은 음식부터 선택: 탐욕법
for (let i = 0; i < ratioList.length; i++) {
if(budget >= PRICE_LIST[ratioList[i].index]) {
budget -= PRICE_LIST[ratioList[i].index];
totalProtein += PROTEIN_LIST[ratioList[i].index];
foodCount++
if(foodCount === MAX_FOOD_COUNT) {
break;
}
}
}
/*
1차 선택: index 4 (46g) - 5600원 사용, 남은 예산 9400원
2차 선택: index 3 (36g) - 5000원 사용, 남은 예산 4400원
3차 선택: index 2 (17g) - 4500원 사용, 부족
최종 결과: 46g + 36g = 82g의 단백질 획득
*/
//최대 섭취 가능 단백질 함량: 99
console.log(totalProtein)
전체적인 정렬의 흐름은 아래와 같다.
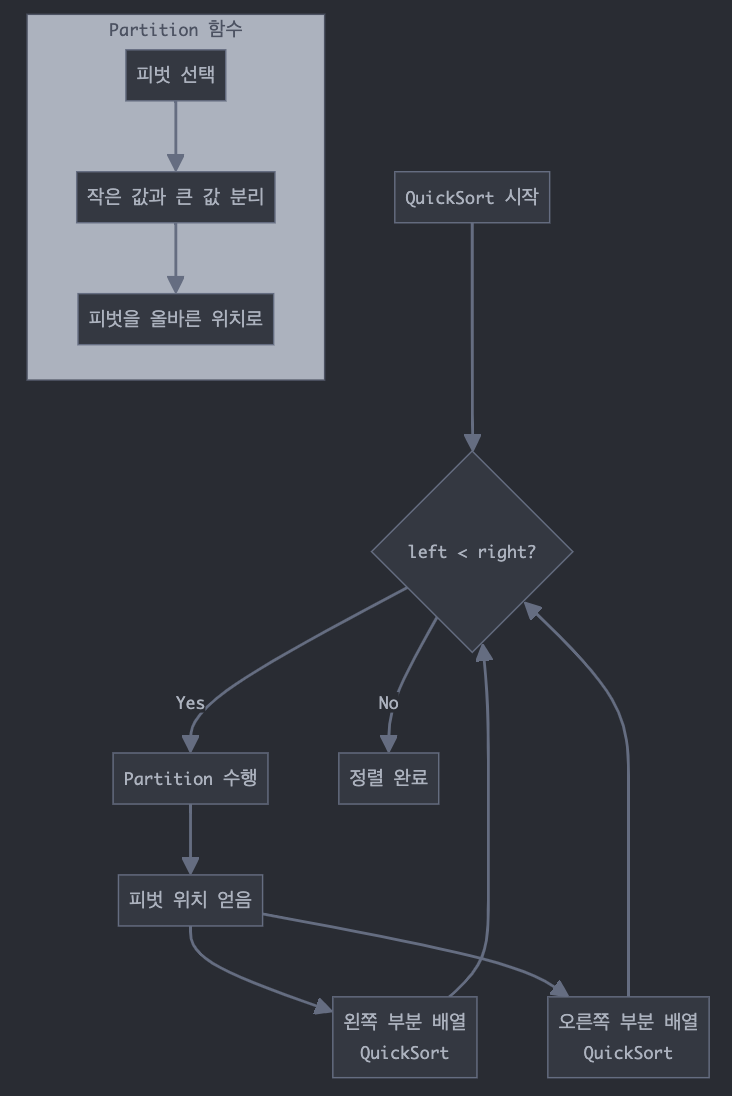
이 때 partition 함수의 과정은 아래와 같다.
- 피벗을 기준으로 큰 값들은 왼쪽으로
- 작은 값들은 오른쪽으로 모으는 것
- 최종적으로 피벗의 올바른 위치를 찾는 것
이 과정이 재귀적으로 반복되면서 전체 배열이 정렬 된다. 위 예시에서는 가성비(ratio)를 기준으로 정렬하되, 큰 값이 앞으로 오도록 정렬 한다.

// 초기 상태
pivot = 0.0081 (마지막 요소)
i = 0
[0.0017, 0.0037, 0.0049, 0.0072, 0.0082, (0.0081)]
i,j
// j=0: 0.0017 < 0.0081, 교환 없음
[0.0017, 0.0037, 0.0049, 0.0072, 0.0082, (0.0081)]
i j
// j=1: 0.0037 < 0.0081, 교환 없음
[0.0017, 0.0037, 0.0049, 0.0072, 0.0082, (0.0081)]
i j
// j=2: 0.0049 < 0.0081, 교환 없음
[0.0017, 0.0037, 0.0049, 0.0072, 0.0082, (0.0081)]
i j
// j=3: 0.0072 < 0.0081, 교환 없음
[0.0017, 0.0037, 0.0049, 0.0072, 0.0082, (0.0081)]
i j
// j=4: 0.0082 > 0.0081, i와 교환
[0.0082, 0.0037, 0.0049, 0.0072, 0.0017, (0.0081)]
i j
// 마지막: i위치와 피벗 교환
[0.0082, 0.0037, 0.0049, 0.0072, 0.0081, 0.0017]
탐욕법을 사용한 부분의 로직은 아래와 같다.
- 함량 리스트를 순회한다.
- 만약 함량 리스트의 인덱스를 공유하는 "가격 리스트"의 원소(개별 음식의 가격)이 예산보다 작다면, 예산에서 해당 가격을 빼버린다.
- 총 단백질에 함량 리스트의 인덱스를 공유하는 "단백질 리스트"의 원소(개별 음식의 단백질 함량)을 더한다.
- 음식개수에 1 증가해준다.
- 만약 음식개수가 최대 음식개수와 같아지면 반복문을 탈출한다.
- 그렇지 않다면 다시 반복문을 실행한다.(만약 음식 개수 제한 조건이 없다면, 또는 구매하지 못한 경우에도 순회는 끝까지 진행될 것이다.)
따라서 아래와 같이 예산이 가격 리스트의 최솟값보다 작아지는 경우 순회를 탈출하는 로직을 추가할 수도 있다.
let totalProtein = 0;
let foodCount = 0;
for (let i = 0; i < ratioList.length; i++) {
// 남은 예산이 가장 싼 음식보다 작으면 종료
if(budget < Math.min(...PRICE_LIST)) {
break;
}
if(budget >= PRICE_LIST[ratioList[i].index]) {
budget -= PRICE_LIST[ratioList[i].index];
totalProtein += PROTEIN_LIST[ratioList[i].index];
foodCount++
if(foodCount === MAX_FOOD_COUNT) {
break;
}
}
}
참고1.
로 여기서 Math.min() 함수에 배열을 넣어줄 때는 Math.min(PRICE_LIST) 해주지 않고, 스프레드 연산자인 '...'를 사용하여 Math.min(...PRICE_LIST) 방식으로 넣어주어야 한다. 배열 그 자체를 넣어주면 비교할 대상이 존재하지 않기 때문에 NaN을 반환하게 된다. 그러나 스프레드 연산자를 이용해서 넣어주면 스프레드 연산자가 배열을 펼쳐주기 때문에 각 원소를 비교할 수 있게 되므로 올바른 최솟값을 구할 수 있다.
예를 들어
Math.min([1, 5, 3]) : NaN을 반환한다.
Math.min(...[1, 5, 3]): Math.min(1, 5, 3)으로 변환되어 비교가 가능해진다.
참고2.
NaN 을 반환하는 것 자체는 에러가 아니다. 왜냐하면 NaN(Not a Number)는 값일 뿐이기 때문이다. NaN 이 에러 발생 가능성을 높이기 때문에 주의해야 하는 것이다.
NaN은:
- 숫자 타입의 특수한 값
- 수학적 연산이 불가능/무의미함을 나타내는 값
- 비교 연산이 불가능한 값
// NaN이 반환되는 상황들 - 모두 정상적으로 실행됨
Math.min([1, 2, 3]) // NaN
parseInt("hello") // NaN
0/0 // NaN
// NaN을 포함한 추가 연산도 가능 - 에러 없이 실행됨
let result = Math.min([1, 2, 3]) + 5; // NaN + 5 = NaN
console.log(result); // NaN
// 다만 이후 연산에서 의도치 않은 결과가 발생할 수 있음
if(result > 10) { // NaN > 10 은 항상 false
// 이 코드는 절대 실행되지 않음
}
예제2)
/*
퀵 정렬을 알고 있는 배송기사
-동선을 최소화 하면서 타워에 오른다.
- 단, 모든 층에 방문할 수 없다.10층 이상부터는 5층 단위로만 방문이 가능하다.
- 예를 들어 16, 17층에 배송해야 한다면 15층에 놓아두면 된다.
*/
let deliveryFloors = [5, 2, 8, 6, 1, 9, 3, 20, 18, 42, 43, 15, 7, 11, 5];
// 10층 이상은 5의 배수로 변환
deliveryFloors = deliveryFloors.map(floor =>
floor >= 10 ? Math.floor(floor/5) * 5 : floor
);
// 중복 층 제거
deliveryFloors = [...new Set(deliveryFloors)];
// 수정된 퀵 정렬
function quickSort(arr) {
if(arr.length <= 1) {
return arr;
}
const pivotIndex = Math.floor(arr.length / 2);
const pivot = arr[pivotIndex];
const left = [];
const right = [];
// 피벗을 제외한 나머지 요소들을 분할
for(let i = 0; i < arr.length; i++) {
if(i === pivotIndex) continue; // 피벗은 건너뛰기
if(arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return [...quickSort(left), pivot, ...quickSort(right)];
}
console.log(quickSort(deliveryFloors));
// 10층 이상 5의 배수로 변환 후: [5, 2, 8, 6, 1, 9, 3, 20->20, 18->15, 42->40, 43->40, 15->15, 7, 11->10, 5]
// 중복 제거 후: [5, 2, 8, 6, 1, 9, 3, 20, 15, 40, 7, 10]
// 정렬 후: [1, 2, 3, 5, 6, 7, 8, 9, 10, 15, 20, 40]
* 피벗 인덱스를 0으로 놓고 하지 않고, 중앙값으로 진행하는 경우에는 해당 인덱스가 등장했을 때 contiune를 사용해서 건너띄어 주어야 한다. 그렇지 않으면 같은 값을 계속해서 비교하게 되므로 분할되지 않고 같은 크기의 배열이 계속해서 생겨나게 됨.
아래와 같이 개선할 수도 있음.
let deliveryFloors = [5, 2, 8, 6, 1, 9, 3, 20, 18, 42, 43, 15, 7, 11, 5];
// 10층 이상은 5의 배수로 변환
deliveryFloors = deliveryFloors.map(floor =>
floor >= 10 ? Math.floor(floor/5) * 5 : floor
);
// 중복 층 제거
deliveryFloors = [...new Set(deliveryFloors)];
// 개선된 퀵 정렬
function quickSort(arr, left = 0, right = arr.length - 1) {
if(left >= right) return arr;
// 1. 랜덤 피벗 선택으로 성능 개선
const randomPivot = Math.floor(Math.random() * (right - left + 1)) + left;
[arr[right], arr[randomPivot]] = [arr[randomPivot], arr[right]];
// 2. 파티션 함수로 분리하여 가독성 향상
const pivot = partition(arr, left, right);
// 3. 추가 배열 생성 없이 인플레이스(in-place) 정렬
quickSort(arr, left, pivot - 1);
quickSort(arr, pivot + 1, right);
return arr;
}
function partition(arr, left, right) {
const pivot = arr[right];
let i = left - 1;
// 4. 최적화된 파티션 로직
for(let j = left; j < right; j++) {
if(arr[j] <= pivot) {
i++;
[arr[i], arr[j]] = [arr[j], arr[i]];
}
}
[arr[i + 1], arr[right]] = [arr[right], arr[i + 1]];
return i + 1;
}
console.log(quickSort(deliveryFloors));
아래와 같이 더욱 개선도 가능
function quickSort(arr, left = 0, right = arr.length - 1) {
while(left < right) {
// 작은 부분 배열은 삽입 정렬 사용
if(right - left < 10) {
insertionSort(arr, left, right);
return arr;
}
const pivot = partition(arr, left, right);
// 더 작은 부분을 먼저 정렬 (tail recursion 최적화)
if(pivot - left < right - pivot) {
quickSort(arr, left, pivot - 1);
left = pivot + 1;
} else {
quickSort(arr, pivot + 1, right);
right = pivot - 1;
}
}
return arr;
}'Algorithm&Data structure > JS alg.' 카테고리의 다른 글
| 기수정렬(Radix sort) (5) | 2024.10.28 |
|---|---|
| 힙 정렬(heap sort) (0) | 2024.10.26 |
| 합병정렬 일반형 (2) | 2024.10.23 |
| 삽입정렬 일반형 (0) | 2024.10.21 |
| 버블정렬 일반형 (0) | 2024.10.21 |

