
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 스프링부트핵심가이드
- 스프링 시큐리티
- 서버설정
- 알파회계
- iterator
- 구멍가게코딩단
- 네트워크 설정
- resttemplate
- 친절한SQL튜닝
- 리눅스
- Kernighan의 C언어 프로그래밍
- network configuration
- 페이징
- 코드로배우는스프링부트웹프로젝트
- GIT
- 데비안
- baeldung
- 처음 만나는 AI 수학 with Python
- 티스토리 쿠키 삭제
- 목록처리
- ㅒ
- /etc/network/interfaces
- 이터레이터
- 처음 만나는 AI수학 with Python
- 자료구조와함께배우는알고리즘입문
- d
- 선형대수
- 코드로배우는스프링웹프로젝트
- 자료구조와 함께 배우는 알고리즘 입문
- 자바편
Archives
- Today
- Total
bright jazz music
7. 1 네이버에서 KOSPI200 지수 수집하기(html크롤링) 본문




#!/usr/bin/env python
# coding: utf-8
# In[21]:
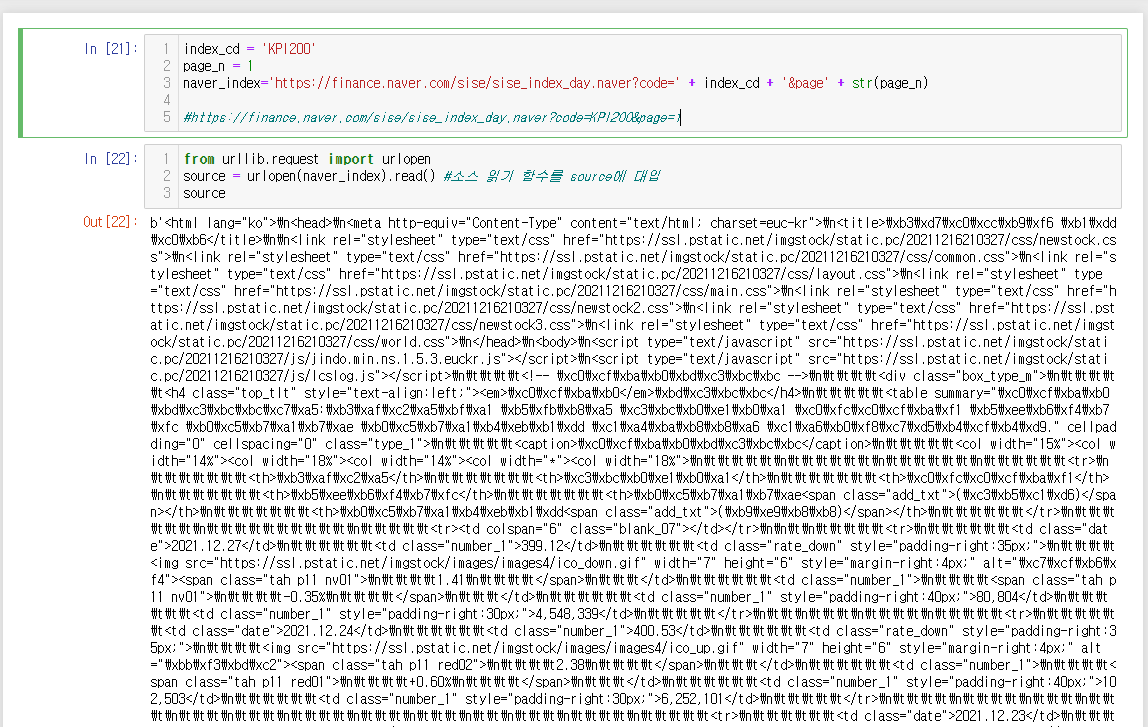
index_cd = 'KPI200'
page_n = 1
naver_index='https://finance.naver.com/sise/sise_index_day.naver?code=' + index_cd + '&page' + str(page_n)
#https://finance.naver.com/sise/sise_index_day.naver?code=KPI200&page=1
# In[22]:
from urllib.request import urlopen
source = urlopen(naver_index).read() #소스 읽기 함수를 source에 대입
source
# In[23]:
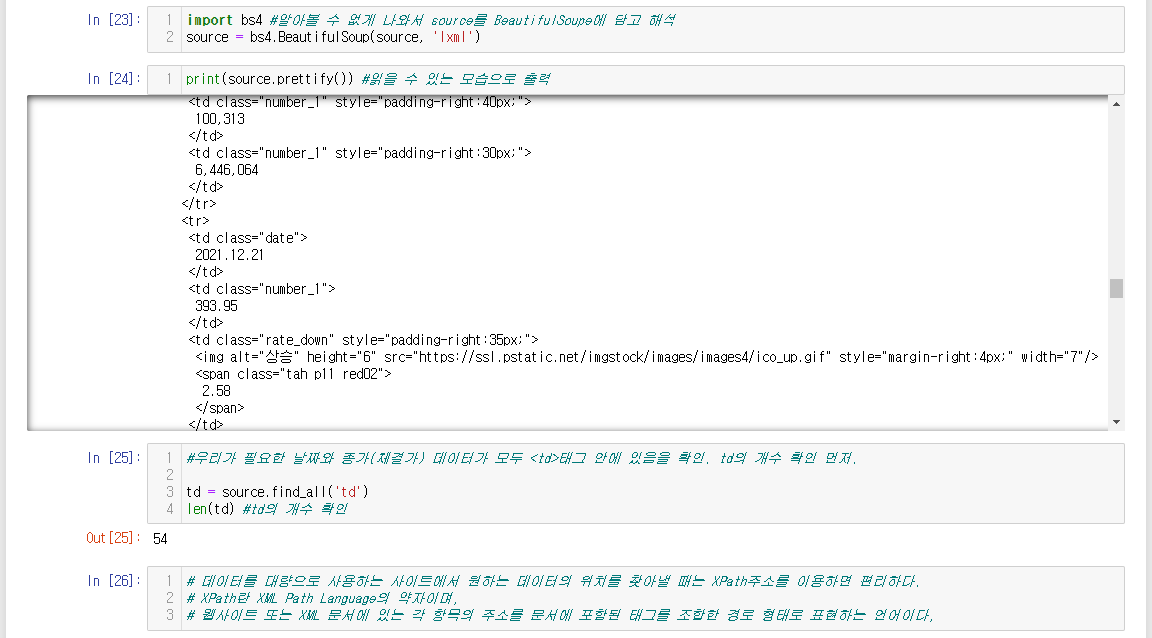
import bs4 #알아볼 수 없게 나와서 source를 BeautifulSoupe에 담고 해석
source = bs4.BeautifulSoup(source, 'lxml')
# In[24]:
print(source.prettify()) #읽을 수 있는 모습으로 출력
# In[25]:
#우리가 필요한 날짜와 종가(체결가) 데이터가 모두 <td>태그 안에 있음을 확인. td의 개수 확인 먼저.
td = source.find_all('td')
len(td) #td의 개수 확인
# In[26]:
# 데이터를 대량으로 사용하는 사이트에서 원하는 데이터의 위치를 찾아낼 때는 XPath주소를 이용하면 편리하다.
# XPath란 XML Path Language의 약자이며,
# 웹사이트 또는 XML 문서에 있는 각 항목의 주소를 문서에 포함된 태그를 조합한 경로 형태로 표현하는 언어이다,
# In[27]:
# /html/body/div/table[1]/tbody/tr[3]/td[1] #사이트의 xpath.
# 사이트(html) => body => div => table(첫 번째) => tr(세 번째) => td(첫 번째) 순서로 찾아가라는 뜻.
# tbody는 실제 코드 내용이 아니라 테이블이 시작된다고 알려주는 표시
# 찾아가는 방법은 값이 하나인 경우에는 find(태그명), 여러 개인 경우 find_all(태그명)[순서] 사용
# 단, XPath는 숫자를 1부터 세고, python은 0부터 세므로, xpath의 숫자에서 -1을 해줘야 한다.
source.find_all('table')[0].find_all('tr')[2].find_all('td')[0]
#첫 번쨰 테이블의 세 번째 tr의 첫 번째 td를 찾으라는 뜻
# In[28]:
# <td class="date">처럼 class이름을 이용해 특별히 이름을 붙인 td 태그는 이름을 지정해서 뽑아낼 수도 있음
# 이 경우 td 앞에 붙는 태그를 생략할 수 있음
d = source.find_all('td', class_='date')[0].text
d
# In[29]:
#원하는 데이터를 찾았지만 네이버의 날짜 형식은 파이썬의 날짜형식과 다름. 따라서 파이썬 형식으로 변경 필요
# ' .' 으로 구분된 년월일을 분리하고 이를 datetime 라이브러리를 이용하여 date 형식으로 변경
import datetime as dt
# In[30]:
yyyy = int(d.split('.')[0]) # 문자열.split(구분자) 구분자를 기준으로 문자열을 분해. 여기서는 년,월,일로.
mm = int(d.split('.')[1]) # dt.date(년, 월, 일) 함수를 이용하여 문자열을 날짜 형식으로 변경
dd = int(d.split('.')[2])
this_date = dt.date(yyyy, mm, dd)
this_date
# In[33]:
# 날짜 정보를 date형식으로 변경할 일이 계속 생기므로 함수를 만들어 적용
def date_format(d):
d = str(d).replace('-', '.') #문자열.replace('A', 'B') 문자열 A를 B로 변경해줌.
yyyy = int(d.split('.')[0])
mm = int(d.split('.')[1])
dd = int(d.split('.')[2])
this_date = dt.date(yyyy, mm, dd)
return this_date
# In[35]:
#함수를 만들었으니 지수를 가져올 차례. 해당 일자의 종가지수를 가져와야 한다.
# /html/body/div/table[1]/tbody/tr[3]/td[1] #사이트의 xpath.
this_close = source.find_all('tr')[2].find_all('td')[1].text
this_close = this_close.replace(',' , '') #쉼표(,) 제거
this_close = float(this_close)
this_close
# In[37]:
#태그에 클래스 네임이 있으므로 더 쉽게 찾을 수도 있음
p = source.find_all('td', class_='number_1')[0].text
p
# In[41]:
#페이지에 있는 모든 날짜와 가격 불러오기
dates = source.find_all('td', class_='date')
prices = source.find_all('td', class_='number_1')
# In[40]:
len(dates) #날짜의 개수. 한 페이지에 6개 나온다
# In[45]:
len(prices)
# 체결가, 등락률, 거래량, 거래대금이 모두 <td class="number_1">를 사용한다. 이중 첫 번째 값만 필요하다.
#0,4,8 ... 따라서 4*6 = 24
# In[47]:
for n in range(len(dates)): # dates 개수만큼 반복
this_date = dates[n].text # n번째 dates 값 추출
this_date = date_format(this_date) #날짜 형식으로 변환
this_close = prices[n*4].text #0, 4, 8 ... 등 4의 배수에 해당하는 종가지수 추출
this_close = this_close.replace(',' , '') #쉼표(,) 제거
this_close = float(this_close) #숫자 형식으로 변환
this_close
print(this_date, this_close)
# In[87]:
#페이지 표시에서 '맨뒤' 버튼에 우클릭 하고 검사 누르기
# <a> 태그는 <td class="pgRR"> 태그이다. 따라서 다음과 같이 하이퍼 링크 주소를 따올 수 있다,
paging = source.find('td', class_='pgRR').find('a')['href']
paging
# In[88]:
#페이지 주소만 따올 거라면
paging = paging.split('&')[2]
paging
# In[89]:
#페이지 번호만 따기
paging = paging.split('=')[1]
paging
# In[92]:
#마지막 페이지를 뽑는 과정을 종합해 보면
last_page = source.find('td', class_='pgRR').find('a')['href']
last_page = last_page.split('&')[2]
last_page = last_page.split('=')[1]
last_page = int(last_page)
last_page'기타 > 파이썬 금융 데이터 분석' 카테고리의 다른 글
| 7. 금융공학 모델링 (0) | 2021.12.25 |
|---|---|
| 6. 파이썬 실습 (0) | 2021.12.25 |
| 5. 주식 엑셀(구글 시트) 실습 (0) | 2021.12.21 |
| 4.3 산포도, 회귀분석, 추세선, 결정계수 (0) | 2021.12.21 |
| 4. 주가지수의 종류 (0) | 2021.12.10 |
'기타/파이썬 금융 데이터 분석' Related Articles
more




Comments